

In our tech-driven world, businesses rely heavily on software systems. In turn, they become more complicated and linked together. That’s why it is vital to ensure that systems are dependable.
Nowadays chaos engineering is an effective way to test and enhance applications. By introducing real-life disruptions under control, chaos testing helps businesses discover their weaknesses. This practice allows one to prepare for unexpected failures and handle challenges better.
What is Chaos Testing?
Chaos testing is a controlled method of introducing failures into a system to observe its response under stress. The goal is to see if the system can continue to operate and recover well. The problems we create can mimic real-life situations or exceed them at times.
For example, these issues could stem from performance issues when numerous users try to access the system simultaneously, like stress testing.
On the other hand variations — infrastructure faulty, poor internet, server equipment. Some data problems such as network latency or network outages. Randomly turning off different parts of a system, like smoke testing.
These help clarify the determination of the system’s steady state.
Let’s define Chaos Testing Definition in the QA testing Landscape 😃
In software development, chaos testing is also well-known as chaos engineering testing, even the second definition is more common. Testers who conduct it — chaos engineers. It is crucial in providing a system’s resilience and positive user experience of the end users.
This methodology is different from traditional structured testing types. Primarily, it is stability validation, while traditional testing methods evaluate both functional and non-functional aspects of software. Instead of only checking how a system should work within pre-defined test scenarios, chaos testing shifts testing focus to preventive validation. The most similar testing type is monkey testing.
So, it is a proactive testing method that uses fault injection to conduct safe tests in smaller system parts or users by purposefully detecting weak areas and fixing these areas before they turn into big problems. The most similar testing type is monkey testing.
Meaning of Chaos testing experiment
Regarding experiments, they can include many different things… being easier or harder to implement. Here are a few examples:
Types of Chaos Experiments
- Database or server shutdowns. This means quickly causing failures in the system.
- Custom code injection. We add code to see how it impacts stability.
- Network latency increases. We check how the system works with slow communication.
- Resource usage increases. Pushing CPU or memory to their limits.
- DDoS attacks. This tests the application vulnerabilities when there is a lot of traffic,
equally to security testing. - External dependency failures. We see what happens when third-party services don’t work.
- Configuration alterations. We change settings to check how well the system adapts.
📖 Historical context & chaos engineering evolution
Chaos testing began at Netflix in 2010 after they moved to AWS (Amazon Web Services). Before this, they experienced a system outage with their virtual machines. To avoid similar problems, Netflix created a tool called Chaos Monkey. This tool intentionally creates disruptions in the system. In 2012, Netflix made Chaos Monkey available to the public on GitHub under an Apache 2.0 license. Now it is a popular chaos testing framework. It allowed more IT teams to use chaos engineering now. A major development came when Netflix introduced Chaos Kong. This tool showed how valuable chaos testing is during a regional outage of DynamoDB in 2015. Thanks to this testing, Netflix had less downtime than other AWS users more.
Two Major Principles Founded by Netflix:
- No system should ever have a single point of failure.
- A single point of failure refers to the possibility that one error or failure could lead to hundreds of hours of unplanned downtime.
The Essence of Chaos Engineering in Software Development
Chaos testing helps teams:
✅ Detect hidden failures before they lead to a negative user experience
✅ Improve system immunity and recovery mechanisms from incidents on the live version
✅ Enhance system resilience for high-availability applications
✅ Better deal with security surprises and possible DDoS attacks
✅ Prevent large breakdowns or service issues
✅ Prepare teams for real-world incidents in advance
✅ Enhance design
✅ Shows teams how to boost their systems overall
What is the Role of Chaos Testing Experiments?
✅ Highlights issues that might happen.
✅ Provides valuable info on the system state otherwise it might be overlooked.
✅ Instantly provides insights that directly influence software enhancement.
End up, it impacts building systems that can meet the growing needs of the digital world and increase customer satisfaction.
Chaos testing and Test Pyramid Layers
Chaos testing identifies vulnerabilities across all layers of the Testing Pyramid and brings system tolerance. This means teams can strengthen system reliability at every level — from individual functions to full application resilience.
Look in detail 👀
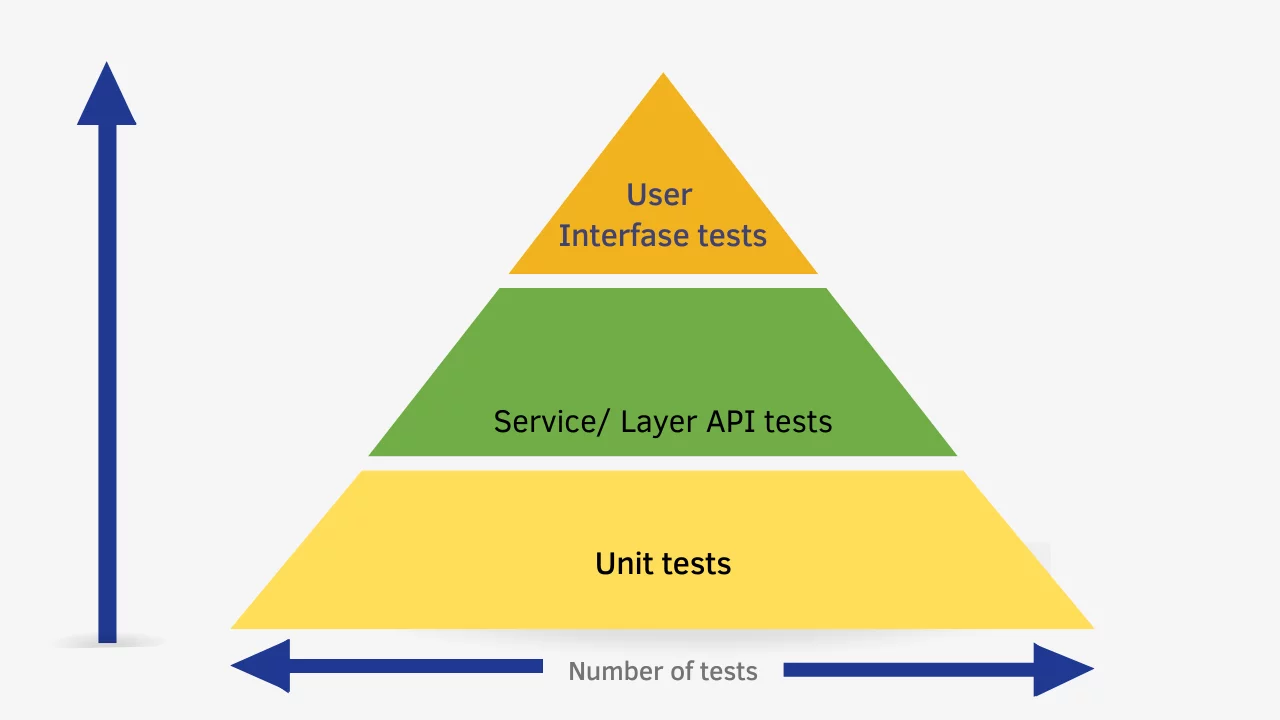
#1: Unit Tests + Chaos Testing (Base of the Pyramid)
Objective: Identify and handle failures at the code level before they escalate.
- Unit tests focus on isolated functions or components.
- Introducing chaos at this level means simulating unexpected inputs, edge cases, or error scenarios.
- Tools like Junit (Java), PyTest (Python), or Jest (JavaScript) can be used for injecting faults.
Examples
→ Simulating a divide-by-zero exception in a function.
→ Injection of invalid or corrupted data to test how methods handle failures.
#2: Integration Tests + Chaos Testing (Middle Layer)
Objective: Ensure that services and components interact correctly under failures.
- Integration tests validate data flow and service dependencies.
- Chaos testing at this level includes network failures, API timeouts, or database crashes.
- Use tools like Toxiproxy or Chaos Mesh to inject failures.
Examples
→ Simulating a database connection failure and observing how the application handles retries.
→ Introducing latency in an external API to test fallback mechanisms.
#3: End-to-End (E2E) Tests + Chaos Testing (Top of the Pyramid)
Objective: Assess full system resilience under real-world conditions.
- E2E tests validate user journeys and system-wide functionality.
- Chaos testing at this level involves killing services, reducing resources, and testing disaster recovery.
- Gremlin, Chaos Monkey, and LitmusChaos can be used for system-wide chaos engineering.
Examples
→ Termination of a microservice instance and check if the system auto-recovers.
→ Simulating high CPU/memory usage on a cloud instance to test performance under load.
Chaos Testing Implementation: Step-by-Step Approach
Effective chaos testing follows structure and relies on some important ideas. Planning it properly is important to provide better outcomes. Therefore, chaos engineering involves a systematic process. A key goal is reaching Quality Assurance. Keep on reading to explore its details ⬇️
#1 Step: Clarify system design
Chaos test cases are based on the system’s design. You need to understand how the system is built and how its parts are connected. This knowledge helps you find failure points. It also lets you create effective test scenarios that focus on these issues.
#2: Identifying Potential System Vulnerabilities
Before you begin experiments, you need to suppose potential vulnerabilities. Look at major parts or connections that could cause huge problems if they do not function properly.
#3 Step: Set High-level Testing Goals
You need to set a few specific goals for what success looks like. Start by deciding what you want to test in your experiment.
Examples of objectives for validation chaos performance testing
— What is the measure system’s availability?
— How fast does it perform?
— How is it secure?
#4 Step: Formulate Hypothesis
Hypothesis is a structured assumption about how a system should behave under specific failure conditions. You must define expectations of what should happen when you inject controlled disruptions.
Typical hypothesis structure
We believe that when [failure condition happens] the system will [expected behavior]
Example Hypotheses within acceptance criteria
If network connectivity between two services is lost, the system will retry requests and eventually recover (Network Partitioning experiment).
#5 Step: Make Evaluation, Risk Analysis and Prioritization
This step empowers you to improve your chaos engineering efforts. Focus on the most important issues first. Think about the damage bugs might cause. Rank them by risk. Keep in mind a blast radius. This means the part of the system that the experiment will impact.
#6 Step: Build your Test Strategy
Structured test plan is vital. A clear document will help you repeat the experiment. It helps in understanding the results. Also, repeat your steps in the future. Now, let’s specify your steps:
- Write your experiment plan
- Break into the parts
- List the possible failures you will examine
- Write test cases
- Share what you expect to discover (expected results).
#7 Step: Execute your experiments
The test is carried out in a controlled environment with the system’s monitoring response closely. It is important to document every detail of the experiment. Open detected defects.
🔴 Remember, chaos engineering is not only about crashes. It is also about watching how the system behaves in tough situations.
#8 Step: Monitoring Results and Analyzing System Responses
During this phase, detail Reports & Analytics play a key role in building a solid App. They help you see how the system reacts during the test. You can spot any unusual changes during testing.
Good monitoring tools track key metrics while you test. They might include response times and usage, error rates, or other more specific measurements.
#9 Step: Make improvements based on Metrics & Reviews
Review the outcomes, make improvements, and grow if necessary. See if the system handles the issues effectively or if it falls short of what you expected.
#10 Step: Find new factors
See how possible failures might impact the system.
#11 Step: Repeating until the hypothesis is proven
The refined system is tested repeatedly under the defined conditions until it confirms the hypothesis. Chaos testing is about taking your plans and turning them into simple actions again and again.
This case study shows ways to enhance and tells you if your chaos strategy works properly.
Core Principles of Chaos Engineering Behind Effectiveness
Best Practices of Chaos Testing
- Begin with small tests first.
- Then, gradually widen the blast radius.
- Understand the effects better.
- Use the testing Pyramid to maximize the benefits of chaos testing.
- Use real-life data and situations to test how strong the system is.
- Integrate chaos tests into CI\CD to find issues faster.
Mitigating Risks Associated with Chaos Experiments
- Experiments should take place in a controlled setting.
- Inject chaos tests carefully.
- Use safety steps, like automatic rollback systems.
- Predict a plan to stop the experiment if necessary.
- A thorough check before starting can find what might go wrong.
We must manage risks well so that planned issues do not lead to unplanned problems. Start small to test the strength of an App. Do not create problems in the entire system all at once. Begin by checking one program piece that is not very important. This way, you can see how issues occur in one of the parts of the system and how they may impact other parts or settings. You will also improve how you monitor problems and find solutions without putting the whole app in danger.
As your team feel good about it and gains more confidence, you can increase the blast radius. This means you can take on more complex tasks as you gain experience. You can add more components or even use the whole system and target more users.
Pieces of advice are intended for teams new to chaos engineering practices. Moreover, core principles help experienced development teams manage risks more effectively.
Overcoming Common Challenges in Chaos Testing
Chaos testing can perfectly handle challenges in today’s tech world but has also some challenges. One of the main concerns is the danger of allowing failures to occur on purpose in a system.
Common challenges are:
- A big challenge is getting server logs.
- Another issue is having clear ideas to start.
- It is also hard to manage the resources needed.
- To fix these problems, work with DevOps teams.
- Plan experiments carefully and track the results in detail.
- Make sure you create a plan to reverse any changes you make.
Increasing these negative effects allows you to test in a better way and make problems less likely and the system tougher.
Although, the most challenging is getting help from the people involved. Some of them may feel uncomfortable about causing problems on purpose. To solve this, we should explain the benefits of chaos engineering. It is important to show its value by doing controlled tests. This can help build their trust. We do not want any unexpected shutdowns.
Pros and Cons of Chaos testing
| Advantages | Disadvantages |
| Enhances system resilience and incident response | Can be resource-intensive |
| Reduction in incidents and on-call burdens | Complex to stimulate chaotic scenarios |
| Identifies performance bottlenecks | Can give false positive and negative outputs |
| Increased understanding of system failure modes | Risk of disrupting planned production |
| Boosts Confidence in Deployments | Does not suit smaller applications |
| Improved system design |
Key Tools and Technologies for Chaos Testing
There are many modern tools, frameworks and technologies for chaos testing software. Commonly they use ideas from Netflix innovations and work great in cloud systems. These tools help test different failure situations. Also, mostly they are automation testing tools. The last allows reduce errors made by people and covers more cases when things can go wrong.
Here are some of the best chaos testing tools:
→ Chaos Monkey: This makes it a good choice for teams new to this methodology.
→ Chaos Kong: This tool simulates problems in AWS clouds.
→ Conformity Monkey: This chaos testing tool alerts you about things that are not following the rules.
→ Latency Monkey: This tool adds delays to the network.
→ Doctor Monkey: This one checks and removes instances that are not working well.
→ 10-18 Monkey: This tool tests how the system works with different languages and regions.
→ Janitor Monkey: This tool gets rid of resources that are not being used.
→ Chaos Mesh, Pumba and Litmus Chaos: These tools help test cloud-native and container-based systems.
→ Gremlin. It is a complete platform to see how systems respond to real-world issues. Gremlin has many features. These features include automatic tests and in-depth reports. It also links to popular monitoring tools.
As development teams improve their chaos engineering skills, companies like Microsoft are making it easier to conduct tough tests and manage chaos.
Amazon Web Services (AWS) offers helpful tools like the AWS Fault Injection Simulator and AWS Systems Manager. These tools simplify chaos engineering on the AWS platform.
Putting money into more featured advanced platforms makes sense if the company plans chaos engineering as a lead part of its software development process. Look at the table below, we prepare a short overview:
| Leveraging Open-Source Tools | Paid Platforms for Comprehensive tasks |
| They assist teams in trying out and testing new ideas | These platforms do more than just fault injection |
| Allow companies to try this method without big costs | Automatically set up tests |
| Help to see how quickly the system can bounce back | Give detailed reports and link to monitoring tools |
| There are features for performance engineering too |
Ensuring Team Alignment and Stakeholder Buy-In
Successful chaos engineering is not only about technology. It needs teamwork and support from all. It is important to create a culture where development, operations, and security teams work together. They should feel they each have a part in keeping the system strong.
Good communication is key to getting support and trust from the people involved. You should talk often about the goals, methods, and results of chaos engineering experiments. Explain how AI (Artificial Intelligence) can help find and lower risks. For instance, RedHat use-case of selecting test case scope by AI tool and running them with CI\CD.
It is very important to show that identifying and fixing vulnerabilities early can lead to a stable system. This approach can cut down on downtime and make customers feel more satisfied.
When companies show how chaos engineering helps their goals, teams look for insights to make the software better. It creates a culture of continuous improvement
Expanding chaos engineering testing across industries
This practice is essential not only for tech companies but also for banks, government, finance, healthcare, and schools. It is perfect to use chaos engineering for industries that have strict regulations. In these areas, being dependable and following guidelines is vital — what chaos testing successfully ensures.
On the other hand, this type of testing is advisable for large-scale enterprise software and is generally an exception for small or mid-sized web development projects.
Conclusion
In summary, chaos testing is top for today’s software development. It makes systems stronger, even if they run well. They help find problems before they occur. For successful chaos experiments, you need clear goals. Focus on risks and choose the right tools. It is crucial to reduce these risks. Everyone should understand chaos testing for it to be effective.
Remember, being prepared is the best way to handle issues confidently. If you want to start chaos testing, take your first steps today to create a stronger software system.
Would you like help in setting up a chaos testing strategy for your organization? 🚀 Be free to contact@testomat.io to learn more about our service and test reporting solution.