
In our previous article on the topic “ChatGPT vs. AI Test Management Platforms”, we explored the fundamental differences between using general-purpose AI assistants like ChatGPT versus AI-native QA management systems like Testomat.io. While LLMs offer remarkable flexibility, they often fall short when applied to structured, domain-heavy use cases like software testing. A key challenge we encountered was consistency – how to ensure AI suggestions remain accurate, context-aware, and reliable across test cases, projects, and users.
In this article, we’ll take a deep dive into the technical challenges of implementing AI suggestions and how our team at Testomat.io moved from fragmented experiments to a robust internal prompt framework tailored to engineering-grade requirements.
The Early Stage: Prompt Engineering Chaos
In 2024, “prompt engineering” became the go-to buzzword, yet the community knowledge around it remained shallow. Initial resources mostly covered simple use cases: content generation, summarization, or translation with little insight into complex, data-sensitive workflows.
Before building structured and reliable AI suggestions for QA, we had to understand the anatomy of a good prompt. In early development, our AI outputs were often inconsistent – not because the LLM was “wrong,” but because we lacked control over how we structured the input.
Existing Prompt Frameworks: RACE and RICCE
To move forward, we evaluated well-known prompt engineering frameworks.
RACE: Role – Action – Context – Execute
To apply the RACE framework – Role, Action, Context, and Expectation – your prompt should clearly define:
- Role: Who the AI is supposed to act as
- Action: What task the AI should perform
- Context: The background or examples that guide how the task should be done
- Expectation: What the desired output looks like, including style or format
| Role | “Act as a Lead QA Engineer.” |
| Action | “Generate 3 test case titles for the “Update todo name” functionality based on the provided automated test script.” |
| Context | “To guide the format and tone, here is an example of an existing test title: ‘Verify successful creation of a new todo with valid title’” |
| Execute | “Use the same naming style as existing tests in the test management system.” |
RICCE: Role – Input – Context – Constraints – Evaluation
The RICCE framework helps structure prompts to guide AI more precisely. This framework added necessary constraints and evaluation additional checkpoints:
- Role: Who the AI is supposed to act as
- Input: Specify the input data or materials the AI will work from.
- Context: Provide background or reference info to help guide the AI’s tone, structure, or domain understanding.
- Constraints: Define rules, limits, or formatting requirements.
- Evaluation: Clarify what the output should look like.
| Role | “Act as a Lead QA Engineer.” |
| Input | “Use the provided automated test script for the “Update todo name” functionality.” |
| Context | “Follow the naming and formatting style of our existing test cases. Here is an example:
“Verify successful creation of a new todo with valid title” |
| Constraints | Constraints:
Maintain a consistent tone and structure with the example Focus only on title generation (no descriptions or test steps) Do not invent functionality not implied by the script |
| Evaluation | “Generate exactly 3 test case titles that align with the existing style and focus on various aspects of the “Update todo name” feature.” |
| Full example | You are a test documentation assistant. Use the provided automated test script for the “Update todo name” functionality. Follow the naming and formatting style of our existing test cases. Here is an example:”Verify successful creation of a new todo with valid title” Maintain a consistent tone and structure with the example Focus only on title generation (no descriptions or test steps) Do not invent functionality not implied by the script Expectation: Generate exactly 3 test case titles that align with the existing style and focus on various aspects of the “Update todo name” feature. |
Existing prompt framework imperfections:
- Inconsistent mapping of fields – AI often dropped or mislabeled elements, if they are not well-structured inside prompt text.
- Broken output results – sometimes hallucinated test/suite data, paths or non-existent references, especially in responses involving dynamic content.
- Poor generalization – even with few-shot examples, responses couldn’t adapt to needed output format without required “output” format example.
These issues led us to engineer our own modular, production-ready prompt AI architecture.
Improvement of Existing AI Prompt Framework Solution by the Testomat team
Through experimentation and research, we distilled core prompt components and advanced prompting techniques into a systematic engineering approach.
Working problem suggestion
Working on the next “Suggest Description” for the test case feature based on the test title, I, as usual, started by exploring how to describe the query to the LLM as accurately and precisely as possible. There were many examples on the internet, but they all boiled down to the simplest and most concise version:
| Simple full text of prompt: | Hello ChatGPT. Help me to write a test case description for the [“Update todo name by short invalid Todo’s name with only 2 characters”] test title. Test case following logic: [if the user tries to save a new short Todo’s name (with 2 symbols only), an inline warning message ‘Title field should include at least 5 symbols” + field highlighted with red border should appear]. Maximum 3-5 sentences, clear and understandable to QA team members, considering the test case rule(s). |
If you look at the prompt, everything seems logical: we’re asking ChatGPT to generate a description for a test based on the given parameters (the title) and rules. It’s brilliantly simple. And if you have 10 tests in your system and plenty of free time, you can easily copy the titles and rules, tweak them, and voilà — the perfect prompt for generating “suggest test description” for the tester is found.
| Reusable text of prompt: | Hello ChatGPT. Help me to write a test case description for the “{test title}” test title. Test case following logic: “{test case short description/rules}”. Maximum 3-5 sentences, clear and understandable to QA team members, considering the test case rule(s). |
But is this the perfect formula for a test management system that works with projects containing 10,000 test cases? Let’s slowly break down how we can improve the queries to the LLM so they are reusable, clear, and easy to edit when needed.
Initial Role and Task: Provide the Right Initial Key to Promp
If you have automated test scripts but lack clear test case descriptions, AI can help, but only if you have the well-described task and role to understand what you want from it. I won’t talk much about the role yet, as it would be better to look at an example. And talking about task – right prompt task should be:
- Well-structured, clear and maximum understandable
- Includes some constraints (if available)
- Includes some wishes for the results obtained
The more relevant information you provide to a task, the better the AI can understand and generate accurate results.
| Example of bad-structured task: | Hello ChatGPT. Help me to write a test case description based on the provided automated test script and test title = “Update todo name by short invalid Todo’s name with only 2 characters”. |
| Good Example of well-structured task: | # ROLE: You are a Lead QA Manager responsible for writing a clear test case description based on the provided information # TASK: Review the “Update todo name by short invalid Todo’s name with only 2 characters” test title and **GENERATE a clear, concise, and understandable test case description**. The description should: – Be easily understood by every member of the QA team (regardless of experience level). – Follow the rules and guidelines defined in the initial test information. – Result description **MUST** includes the following attributes: ‘Test Title’, ‘Test Description’, ’Test Data’, ‘Test Steps’, ’Expected Result’ (Ensure clarity, proper grammar, and relevance to the title.) |
Input Data: Give a Clear Input Instructions
If you want to get quality results, you need to include as much “INPUT DATA” and necessary information for the AI as possible in the prompt.
| Example of bad-structured INPUT DATA: | Test case following logic: [if the user tries to save a new short Todo’s name (with 2 symbols only), an inline warning message ‘Title field should include at least 5 symbols” + field highlighted with red border should appear] |
| Example of well-structured INPUT DATA: | # INPUT DATA: * Test Suite = “{suite title}” * Test case logic: “if the user tries to save a new short Todo’s name (with 2 symbols only), an inline warning message ‘Title field should include at least 5 symbols” + field highlighted with red border should appear” |
The more specific and detailed “INPUT DATA” , the more useful and accurate the output will be.
Examples and Output Format: Define the Desired Output Format
Make sure the AI knows how to present the result.
| Example of bad-structured OUTPUT: | <…> (no examples) Return the result in a table with the following columns: ‘Test Title’, ‘Test Description’, ’Test Data’, ‘Test Steps’, ’Expected Result’ |
| Example of well-structured OUTPUT: | # OUTPUT: Follow the output format below:Result description **MUST** includes the following attributes: ## 🖊️ Test Title ## 📋 Test Description ## 📊 Test Data ## 💡Test Steps ## 💡Expected Result |
Screen with the ChatGPT response:
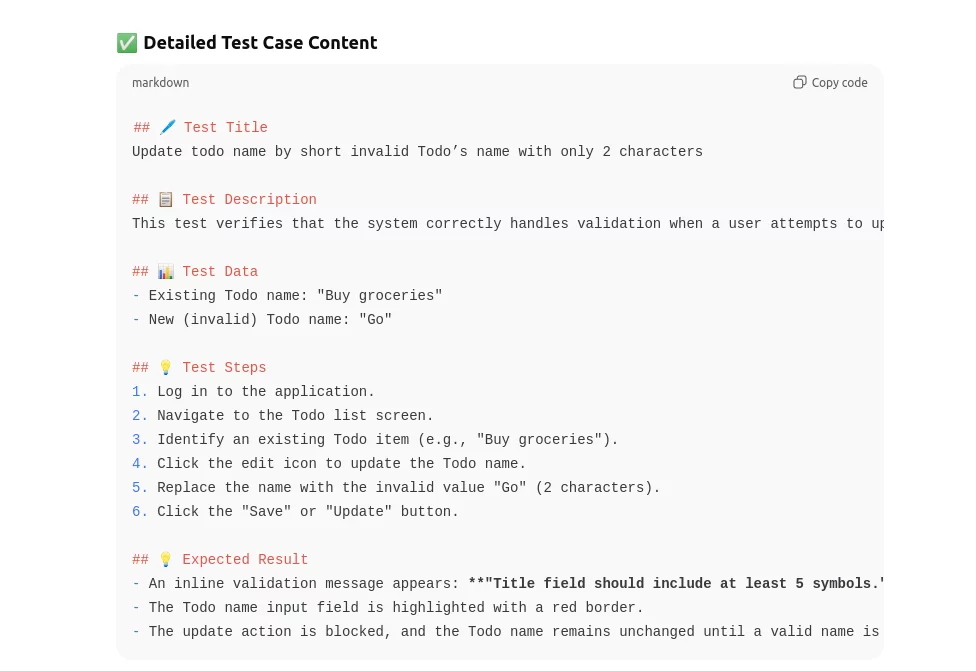
Each of these three elements: Role/Task, Input Data, and Output Format plays a crucial role in helping AI deliver consistent, predictable, and high-quality test documentation.
AI Prompt Testing Methods for Better Model Behavior
To solve more complex use cases – like analyzing large requirement diffs or mapping tests to story updates – we relied on advanced prompting strategies.
Few-Shot Prompting
In cases if you need to get a result based on the existing examples in the system (vague or misaligned outputs) – you should use few-shot prompting techniques . This technique involves providing the model with examples of how similar tasks were previously handled, enabling it to “learn” the desired style or format within the prompt itself.
| Prompt example | Generate 3 test case descriptions for the “Update Todo’s name” functionality by automated test script and titles. The style must match the tests already existing in the test management system. # Good Example-1: ## 🖊️ Test Title Update todo name by short invalid Todo’s name with only 2 characters ## 📋 Test Description This test verifies that the system correctly handles validation when a user attempts to update a Todo item’s name using an invalid input with only 2 characters. According to the application’s validation rules, the Todo name must include at least 5 characters. An inline error message and visual indicator should appear when this requirement is not met. ## 📊 Test Data – Existing Todo name: “Buy groceries” – New (invalid) Todo name: “Go” ## 💡 Test Steps 1. Log in to the application. 2. Navigate to the Todo list screen. 3. Identify an existing Todo item (e.g., “Buy groceries”)… xxx ## 💡 Expected Result – An inline validation message appears: **”Title field should include at least 5 symbols.”** – The Todo name input field is highlighted with a red border. – The update action is blocked, and the Todo name remains unchanged until a valid name is entered. |
That initial prompt information pushed us to go beyond playground-level prompt engineering toward fully modular prompt pipelines, which we’ll describe in the next section.
Practical Tips for Effective AI Prompt Testing
Some general principles we discovered early on:
- Be unambiguous. Instead of “Hello ChatGPT. Help me to write” say **GENERATE a clear, concise, and understandable test case description**
- Guide the task and persona. Phrasing like “You are a Lead QA Manager responsible for…” adds implicit expertise to responses.
- Use clear formatting. Start using bullet points, numbered lists, or explicitly defined sections (e.g., “# Role”, “TASK”) to standardize layout.
- Iterate, test, refine. Treat prompt design like software engineering: test against known inputs, version your prompts, and verify consistency.
Lessons Learned for Engineers Implementing AI
As I mentioned at the beginning, these improvements fit perfectly into our system, because now:
- Prompts are well-structured, and everything is in its place.
- We can dynamically pull the necessary information from the project and, based on it, generate the expected user responses.
- The use of existing project information has become easier.
- The prompt, as the core part, fully performs its function clearly, and all that remains is to correctly process the response and display it on the UI (which we’ll cover a bit later).
Now, let’s summarize everything mentioned above briefly.
Context-Aware Prompt Generation
Prompts are dynamically assembled at runtime using real project metadata. Linked requirements, user-defined test templates, run history, naming conventions, and labels & tags are injected automatically.
Prompt Abstractions
Instead of raw strings, we define well-structured prompt templates in our system code. We can use predefined variables like:
| Get test title | * Test Suite = “#{suite title}” * Test Title = “#{test title}” |
| Get full requirements text | # Test script code: “”” #{test.codeByLine()} “”” |
| Provide project structure | # INPUT DATA: * Project Full Structure: <project_structure> <data:test=888b> TEST TITLE: Cancel Editing Without Saving\n TEST SUITE: Update Todo’s Title\n </data:test> </project_structure> |
| Markdown table with results | #TOP Failed Tests | Test | Priority | Executed At | |——|———-|————-| | Test 1 | High | (10/10/2025) | |
Automatic Format Enforcement
AI responses are validated post-response by our system and try to fix answers based on system internal rules.
If you’re building an AI suggestions platform or similar domain-specific product, here’s what we recommend:
| Challenge | Solution |
| Prompt instability | Define reusable prompt modules with strict input contracts |
| Output hallucinations | Use post-process validators and enforce schema constraints |
| Lack of context | Dynamically inject project-specific data and history |
| Poor relevance | Build semantic filters to select the right test examples |
| Hard to scale | Treat prompts like code – version, test, and modularize |
Conclusion
Integrating AI into QA workflows isn’t just about calling an LLM with a clever prompt. It requires a systematic engineering effort, grounded in software architecture, data modeling, and prompt abstraction.
At Testomat.io, we’ve moved beyond ad-hoc experiments to create a scalable, deterministic, and highly contextual AI assistant – not just an LLM interface, but a smart component deeply embedded in the QA lifecycle.
In the next article, we’ll explore how our custom AI agent works and which general section and trick we have been used to by maximum understandable by LLM.