

Software delivery has changed dramatically over the past decade. Agile development, DevOps practices and CI\CD pipelines have shortened release cycles from months to days or even hours. While this speed allows IT companies to deliver value faster, it also introduces new risks in maintaining software quality. Therefore, modern teams must be on guard to detect risks earlier prioritize testing in the workflow to ensure predictable releases.
As traditional testing approaches become less relevant, teams adopt new ones and rethink their practices with AI. Today, test engineers process retrospective data to turn Quality Assurance from a reactive approach into a strategic, data-driven discipline. This is where predictive analytics in QA becomes valuable — not just end-of-sprint summaries or defect counts.
What is Predictive Analytics in software testing?
Predictive analytics in software testing is the use of historical development and testing data, along with changes in the business environment, to predict defects, test failures, and high-risk areas in software systems before they impact users — helping QA teams focus on the areas which worth prioritising testing or testing more precisely, rather than testing all things randomly for future outcome.
💡 Think of predictive analytics like a health tracker. It analyzes your activity, sleep, breath and heart rate patterns to predict trends — like when you might feel tired or when your performance will improve. Similarly, a predictive analytics dashboard works as a tracker of a software application’s health.
How Predictive Analytics Works in Testing?
Here’s a clear breakdown of how implementing predictive analytics actually functions in testing processes practically:
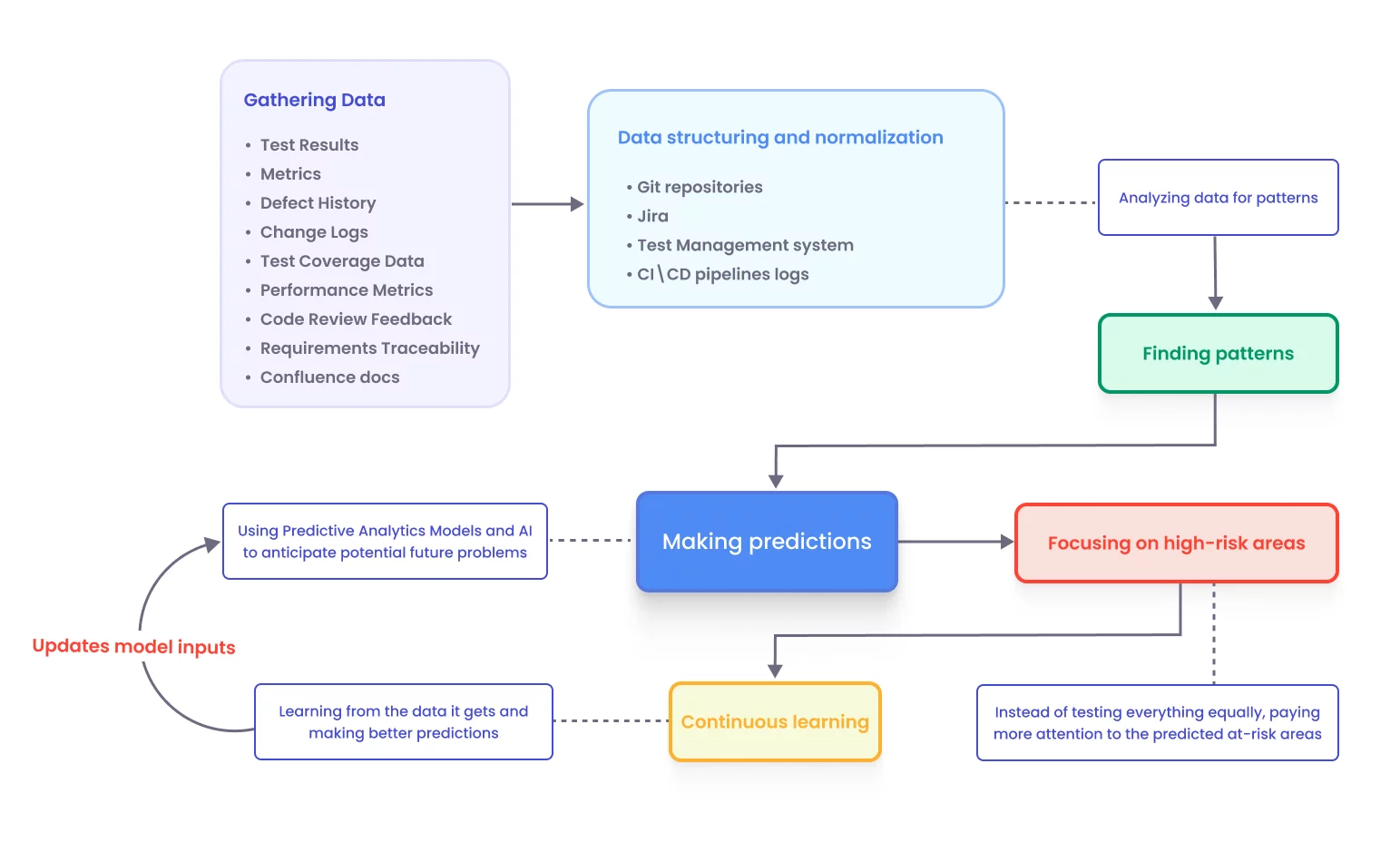
Everything starts with data. We can analyse historical data to extract key insights and signals that underpin predictions of failures, risks, and optimisation opportunities.
Example:
If a specific module has failed 40% of the time after updates, that’s a strong signal.
Typical Data Sources Used
- Test execution results (pass/fail, history)
- Metrics (trends)
- Defect history (where bugs appeared, severity)
- Change logs
- Code repositories context
- Code review feedback (code changes frequency, size and authors)
- CI/CD pipelines
- Test coverage data
- Performance metrics
- Build and deployment logs
- Documentation
Data processing
Raw data is messy, so we need to transform it into meaningful signals. This step makes predictions useful rather than noisy. We can do data structuring with:
- Test management tools (like QASE, Testrail, testomat.io, etc.).
- CI/CD dashboards
- Version control systems (Git commits)
- Issue trackers (Jira defects)
- Code coverage tools
- Static analysis tools
Based on QA data, we have to recognize patterns.
Example:
Large code changes + low test coverage = high failure probability
In practice, to interpret data and generate reliable forecasts, we combine generalized models with heuristic approaches. Let’s look at them more closely:
Popular Predictive Analytics Models
Of course, there are many other types of predictive analytics, but we will focus only on those commonly used by testers 😊
Classification models
Classification models are widely used in software defect prediction (SDP) to guide targeted testing.
- Logistic Regression — simple and interpretable for binary classification (yes vs no, pass/fail, high/low risk)
- Decision Tree — are a model that makes predictions by following a series of if–else rules.
Example:
IF code_changes > 500 lines
AND test_coverage < 60%
→ HIGH RISK
ELSE
→ LOW RISK- Random Forest — the rule of this model is to build multiple decision trees where each tree sees slightly different data + features and combines all predictions. This randomness is the key to better accuracy in comparison with the Decision Tree.
Example:
Tree 1 → High risk
Tree 2 → Medium risk
Tree 3 → High risk
👉 Final prediction: High riskRegression Models
Regression models predict continuous numerical values rather than categories. They model relationships between input features and a target variable.
- Linear Regression is the simplest model that predicts trends of a numeric value by assuming a linear (straight-line) relationship between variables. Think of it like: more code changes — more bugs.
Example:
Predicting defects
x = number of lines changed
y = number of bugs found
👉 The model might learn:
Every +100 lines of code → +2 defectsClustering models
Clustering is a technique that groups data points into segments based on similarity without predefined labels. In testing, it discovers natural groupings. You can group test optimise test suites, find redundant or similar tests, identify components with similar risk profiles, cluster defects by type or origin, failures or understand where failures most frequently occur.
Examples:
Clustering VS Classification
- Classification = This is high risk (you already know labels).
- Clustering = These things behave similarly (you discover patterns).
Outlier models
Outlier or anomaly detection models identify rare, unusual patterns that deviate from normal behavior. It is excellent for proactive defect detection of critical bugs.
Time series forecasting
Forecasting predictive models specialize in predicting future values based on time-ordered past data, accounting for trends and cycles. They are a core part of predictive analytics, often overlapping with regression. We can use it to predict defect trends across releases, estimate future test execution time or release stability.
Example:
Defect rate likely to increase in the next 2 sprints
Prediction and Risk scoring
Once trained, the model starts making predictions like:
→ Which test cases are likely to fail
→ Which areas of the app are high-risk
→ Where bugs are most likely to appear
→ Which builds are unstable
Output often looks like
Risk scores (e.g., 0–100)
Priority rankings
Alerts
Continuous learning loop
The application system is not static — scalability evolves with new features and its codebase over time:
- New test results come in
- Model retrains
- Data mining gets more accurate
Real use cases of what predictive analytics can predict?
Here are some use cases that you might see predictive analytics help within software testing
- Predicting Bug Occurrences: By analysing past bug data, predictive analytics can identify patterns and predict where bugs are likely to occur in the future. For example, if a particular module has frequently had bugs after updates, the model can predict that it might cause issues again.
- Test Case Prioritization: Predictive analytics looks at past testing data and determines which test cases are more likely to fail or catch defects. This way, you can run the most critical tests first.
- Estimating Test Coverage: Predictive models can analyze past test execution results to estimate how much testing is left to do or which parts of the application haven’t been adequately tested.
- Resource Optimization: By predicting the complexity and risk of different parts of the software, predictive analytics helps determine where to allocate resources more effectively. For example, if a feature is predicted to have a high risk of failure, more resources can be dedicated to testing it.
Metrics in Predictive Analysis
Predictive analytics relies on collecting and interpreting meaningful metrics. Metrics are quantifiable indicators derived from historical data that help detect patterns, estimate risk, and make predictions. Think of them as the language your predictive models understand.
Some of the most valuable QA metrics include:
Defect Metrics
- Defect density per module
- Defect discovery trends
- Defect leakage (production defects)
Testing Metrics
- Test coverage
- Automated vs manual test ratio
- Test execution pass/fail rates
Development Metrics
- Code churn (frequency of changes)
- Pull request size
- Commit frequency
Reliability Metrics
- Mean Time to Detect (MTTD)
- Mean Time to Repair (MTTR)
- Production incident frequency
By combining these metrics, predictive models can identify areas with a higher probability of defects or instability.
From reactive traditional QA process: optimize shifting correctly
In traditional QA processes, testing typically occurs after development is completed. Historically, QA teams were responsible for detecting defects after features were implemented. Defects are discovered late, and analysis often happens after issues reach production. Regarding more modern approaches like Agile, testing occurs iteratively on stages of requirement analysis, validation of functionality, smoke testing, regression testing. However, modern QA increasingly focuses on preventing defects before they occur. Definitely, predictive QA introduces a proactive and analytical approach, making testing smart.
| Traditional QA Process | Predictive QA Process |
| Development completes a feature | Collect historical quality and testing data |
| QA tests the feature | Identify patterns in defect distribution |
| Bugs are reported | Analyze code changes and risk areas |
| Fixes are implemented | Predict modules with higher defect probability |
| Testing repeats | Prioritize testing based on risk |
Traditional testing approaches rely heavily on manual analysis and historical experience. While valuable, these methods struggle to keep up with the scale and speed of modern development.
QA Transition from Reactive to Proactive
Reactive QA typically involves:
- Executing test cases
- Reporting defects
- Verifying bug fixes
Proactive QA involves:
- Identifying risky areas in the system
- Monitoring quality metrics
- Advising development teams on potential issues
- Improving test strategies based on historical data
Predictive analytics plays a key role in enabling this transition.
For example, if historical data shows that certain modules frequently produce defects after large code changes, QA teams can increase testing coverage in those areas before release. This approach significantly reduces the likelihood of production failures.
To implement predictive QA, organizations should follow the next steps:
- Centralized test and defect data collection
- Integration between testing, CI/CD, and monitoring tools
- Regular analysis of quality metrics
- Collaboration between QA, developers, and product teams
- This shift helps teams focus testing effort where it provides the highest value and risk reduction.
How the Role of QA Is Changing
The role of QA engineers is evolving beyond traditional test execution. Modern QA professionals increasingly act as quality engineers and data-driven decision makers.
Key QA engineers’ responsibilities now include
- Analyzing quality metrics and trends
- Identifying system risk areas
- Improving test strategies and coverage
- Supporting release decisions
- Collaborating closely with developers and product managers
In predictive QA environments, testers contribute not only through testing activities but also through insights derived from quality data.
This shift requires QA professionals to develop additional skills in:
- Data analysis
- Automation
- CI/CD processes
- System architecture understanding
Here are some ways QA professionals make predictive analytics effective 📃
- Collect structured data by tracking test results, defects and their severity, metrics consistently.
- Remove duplicates and unnecessary tests to ensure your data stays clean.
- Define what you want to predict: bottlenecks, warn of flaky tests or risk of regression failure, e.g.
- Prioritize testing efforts based on predicted risks, focusing on these first.
- Choose the right predictive model.
- Transform data into a meaningful source for the model.
- Identify metrics that actually have an impact.
- Integrate predictions into test strategy, your QA workflow and release decisions.
- Validate and continuously update models.
- Periodically, ask QA experts’ judgments to evaluate the findings for the best results.
- Establish a feedback loop by comparing predicted vs actual results.
- Align your predictions with business goals, not just technical curiosity.
- Make sure your predictions are actionable and understandable for the whole team.
Predictive analytics vs risk management
Predictive analytics is a basis for risk management, both aim to proactively address uncertainty in projects and processes, rather than reacting to problems after they occur. Once again, let’s break down in what way:
| Aspect | Predictive Analytics | Risk Management |
| Focus | Data-driven forecasting | Assessment and mitigation |
| Method | AI, LMM, statistical models | Risk registers, scoring, mitigation plans |
| Outcome | Probabilities (e.g., “this module has 70% chance of failure”) | Decisions (e.g., “run extra tests here, postpone release”) |
| Timeframe | Often real-time or per build | Continuous, project-wide |
| Nature | Reactive + proactive insights | Proactive planning + control |
Essentially, they are complementary approaches: one forecasts risk, and the other acts on it. Their shared goal of improving decision-making and reducing negative outcomes makes them naturally comparable.
Why is predictive analytics important today?
Today’s software systems are more complex than ever. Applications often consist of distributed services, cloud infrastructure, third-party integrations, and multiple client platforms.
Predictive analytics allows teams to:
- Identify high-risk areas of the system
- Forecast potential defect hotspots
- Prioritize testing activities
- Make data-driven release decisions
- Reduce production defects
At the same time, organizations face increasing pressure to:
- Release features faster
- Maintain high system reliability
- Reduce production incidents
- Improve user experience
Instead of asking What broke? teams begin asking What is likely to break next? So, predictive analytics is a way to test software, perform it efficiently and release quality.
Challenges in implementing predictive analytics
Despite its advantages, adopting predictive QA is not without challenges.
Data Quality Problems
Predictive models rely heavily on historical data. If data is incomplete or inconsistent, predictions may be unreliable.
Tool Integration Complexity
Organizations often use multiple tools for testing, CI/CD, defect tracking, and monitoring. Integrating these data sources can be technically challenging.
Cultural Resistance
Transitioning to data-driven decision making may require teams to change established workflows and habits.
Skill Gaps
QA teams may need additional skills in analytics, automation, and data interpretation.
Addressing these challenges requires both technical investment and organizational support.
The Future of Predictive Quality Assurance
The future of predictive QA will increasingly rely on automation, analytics, and artificial intelligence. Predictive models will continue improving with AI.
In the near future, AI QA tools may automatically:
- Detect risky code changes
- Suggest optimal test coverage
- Predict defect probability for new features
- Prioritize automated tests
- Provide quality insights before release
While AI algorithms now provide predictive power, the human element of QA is irreplaceable. QA experts ensure that predictive analytics is applied meaningfully and responsibly, bridging the gap between LMM outputs and real-world product requirements. We will play a critical role in interpreting insights and ensuring that software quality remains aligned with user expectations, and we will be helping organisations move closer to the ultimate goal of QA: delivering reliable, high-quality software with minimal risk.
Conclusion
So, now we know predictive analytics represents a major step forward in modern Quality Assurance. By leveraging historical data, automated testing results, and quality metrics, teams can anticipate potential problems instead of simply reacting to them. The benefits — more reliable releases, fewer production incidents, and better testing efficiency — make this transformation essential for modern software development. However, the transition from reactive testing to proactive quality engineering requires us to have skills with new tools and a data-driven mindset.