Testing LLM applications differs from traditional software testing in fundamental ways. A chatbot built on large language models produces different outputs for identical inputs. Regression tests that worked yesterday fail today without code changes. QA teams trained on deterministic systems struggle with non-deterministic AI responses.
Gartner reports 85% of GenAI projects fail due to inadequate testing or poor data quality. Teams rush LLM applications to production without rigorous testing frameworks. The cost shows up in hallucinated responses, toxic outputs, and user trust erosion.
This guide explains types of LLM testing, evaluation methods, and best practices for testing LLM models effectively. Testing LLM applications requires new approaches while building on testing fundamentals.
What makes testing an LLM different
Unlike traditional software where test LLMs can verify exact outputs, LLM testing involves evaluating probabilistic systems. The same input produces varied responses based on temperature settings, prompt variations, and model state.
| Traditional Software Testing | LLM Application Testing |
| Deterministic outputs | Non-deterministic responses |
| Exact match validation | Semantic similarity evaluation |
| Fixed test cases pass/fail | Probabilistic quality metrics |
| Code logic bugs | Model behavior issues |
| Reproducible failures | Context-dependent failures |
| Linear debugging | Multi-factor analysis |
Traditional testing methods assume stability. Write a unit test once, run it thousands of times with consistent results. Testing LLM models breaks this assumption. LLM outputs change between runs even with identical test cases.
The testing framework must account for this variability. Instead of checking if output equals expected string, LLM evaluation measures semantic similarity, relevance, coherence, and safety. Quality becomes a score on a scale rather than pass/fail binary.
Types of LLM testing essential for production readiness

Testing LLM applications requires multiple testing approaches covering different quality dimensions. Each testing type addresses specific failure modes.
Unit test for LLM components
Unit testing verifies individual LLM calls produce appropriate responses for specific use cases. A unit test for an LLM-powered summarization function checks whether summaries contain key information without hallucinations.
Unit tests work best for testing single LLM calls with clear evaluation criteria, validating that prompt templates produce expected output types, checking output format compliance like JSON structure or length limits, and verifying basic response quality for common inputs.
When writing unit tests for LLM components, create fixed test datasets with known correct answers. Define clear evaluation criteria before writing tests. Use multiple test cases covering normal and edge cases. Automate unit tests in CI/CD pipelines and track test results over time to catch degradation.
Functional test validating end-to-end workflows
Functional testing validates complete user journeys through LLM applications. Unlike unit tests checking individual calls, functional tests verify entire workflows produce useful results. A chatbot functional test sends a conversation sequence and evaluates whether the AI system maintains context, answers questions accurately, and handles conversation flow naturally.
Functional test coverage must include multi-turn conversation handling, context retention across interactions, error handling for unclear inputs, integration with external systems, and overall user experience quality. These tests reveal problems that unit tests miss because they exercise the complete system under realistic conditions.
👀 Read also: Functional Testing Tool: Ensuring Product Reliability with Automation
Performance testing under load
Performance testing for LLMs measures response times, throughput, and resource usage. Load testing validates the system handles expected concurrent users without degradation.
Response latency tracking includes measuring time from user input to first token (Time to First Token), total generation time for complete responses, and latency percentiles at p50, p90, and p99 levels. Throughput capacity testing validates requests per second the system handles, concurrent user capacity, and token generation rate. Resource utilization monitoring covers GPU memory consumption, API costs per request, and infrastructure scaling behavior.
Performance testing reveals bottlenecks before production deployment. A chatbot might work well with 10 test users but collapse under 1,000 concurrent conversations. Testing under realistic load conditions catches these scaling issues early.
Responsibility testing for safety and ethics
Responsibility testing is unique to LLM applications. This involves testing for harmful outputs, biases, toxicity, and inappropriate content generation. Toxicity detection checks for abusive language in responses, hate speech generation, and offensive content across demographics. Bias evaluation examines gender bias in recommendations, racial bias in decision support, and socioeconomic bias in outputs.
Harmful content prevention testing ensures the LLM doesn’t generate dangerous instructions, provide illegal activity support, or produce misinformation. Privacy protection testing validates the system doesn’t leak personal information, expose training data, or mishandle confidential data.
Responsibility testing uses automated LLM testing tools combined with human review. Automated tools catch obvious violations like explicit hate speech or clear privacy breaches. Human evaluators assess nuanced safety issues that require contextual understanding and cultural awareness.
Regression test preventing quality degradation
Regression testing ensures LLM application quality doesn’t degrade over time. Unlike traditional software where regression tests verify code changes don’t break features, LLM testing involves tracking quality metrics across model updates, prompt modifications, and data changes.
A comprehensive regression test suite runs:
- Fixed set of test cases representing core functionality
- Automated LLM testing after every prompt change
- Continuous testing when models update
- Evaluation tracking test results over time
Regression testing catches subtle degradation invisible to individual tests. Response quality might drop 5% with a prompt change. Only regression tracking reveals this pattern.
LLM evaluation metrics and scoring methods
Evaluating LLM outputs requires metrics capturing quality dimensions machines and humans value. Metrics for LLM testing fall into automated and human-assisted categories.
Automated evaluation methods
Similarity testing compares generated outputs to reference answers using semantic similarity scores. BLEU, ROUGE, and BERTScore measure how closely LLM responses match expected answers. This approach works well for translation tasks with clear correct answers, summarization with reference summaries, and question answering with ground truth responses. The limitations include failing to assess quality of creative variations, missing semantic correctness errors, and requiring reference answers that may not exist for all use cases.
Coherence and fluency metrics evaluate text quality without reference answers. Perplexity measures how well LLM outputs match natural language patterns. Lower perplexity indicates more fluent text. Factual accuracy evaluation checks claims against knowledge bases or retrieved context, which is critical for testing LLM applications providing information to users.
LLM as a judge evaluation
Using an LLM to generate evaluations of other LLM outputs has become standard practice. LLM as a judge approach leverages large language models to assess quality dimensions humans judge but machines traditionally can’t measure.
The process starts by generating output from the tested LLM application. That output gets sent to an evaluator LLM with scoring criteria. The evaluator assigns scores on a defined scale. Teams aggregate scores across the test suite and track metrics over time.
Common evaluation dimensions include relevance to input query, correctness of information, helpfulness for user need, tone and style appropriateness, and instruction following accuracy. Best practices involve using powerful models for evaluation like GPT-4 or Claude, writing clear evaluation prompts with examples, validating evaluator judgments against human scoring, tracking evaluator consistency across runs, and considering cost versus accuracy trade-offs.
Human evaluation when needed
Certain quality dimensions require human judgment. Complex use cases, nuanced tone assessment, and specialized domain accuracy need human evaluators with expertise.
Human evaluation best practices:
- Recruit evaluators matching target user demographics
- Provide clear rubrics and scoring guidelines
- Use multiple evaluators per example for consistency
- Calculate inter-rater agreement to verify reliability
- Focus human effort on cases automated testing misses
Balance human and automated testing. Use automated LLM testing for scale and speed. Apply human evaluation where automated methods fail or need validation.
Building effective test suites for LLM applications
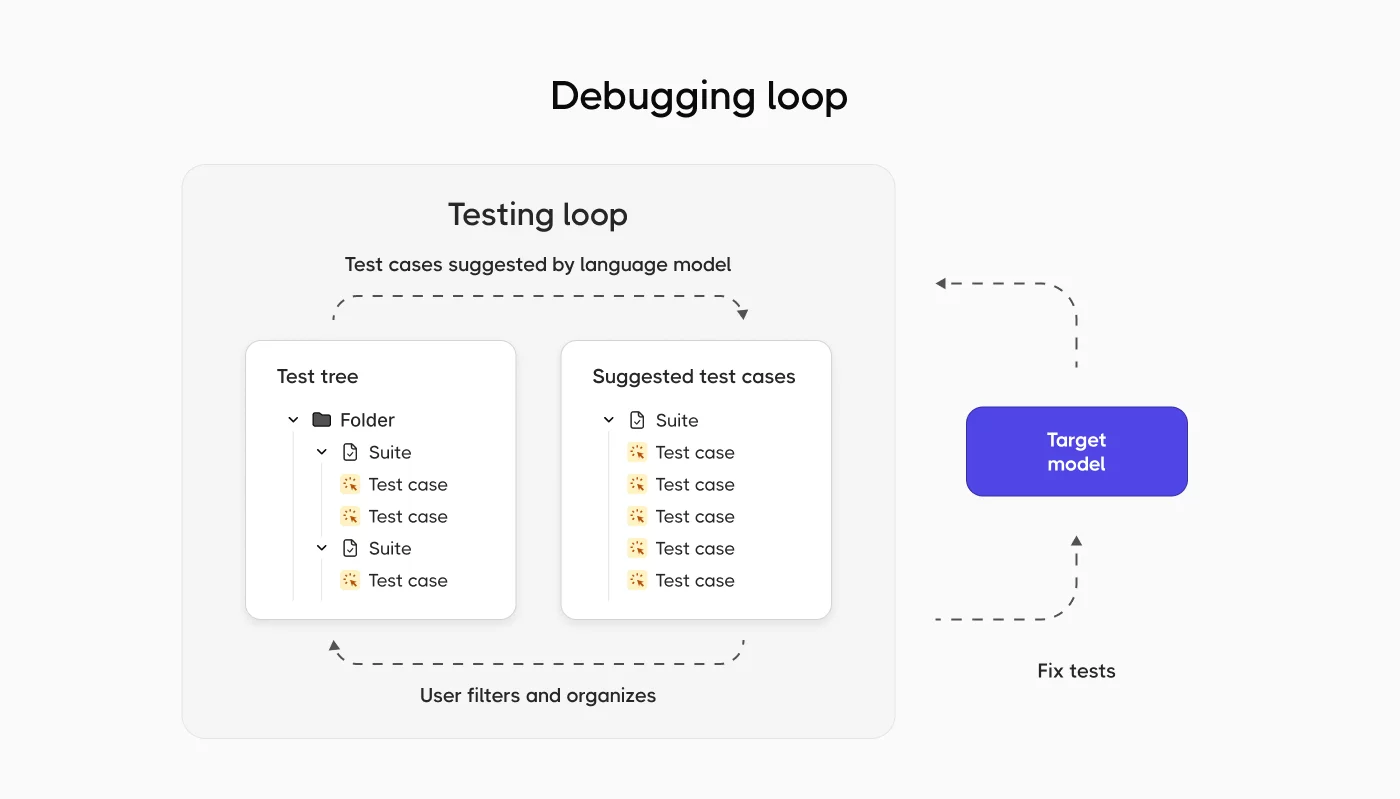
A comprehensive test suite combines multiple testing types with appropriate evaluation methods. Start with specific use case testing before expanding coverage.
Creating test datasets
Test datasets for LLM testing require careful curation. Unlike traditional testing where a few test cases suffice, robust testing demands hundreds or thousands of diverse examples.
Coverage across input variations should include common user queries or prompts, edge cases and unusual inputs, ambiguous or unclear requests, multi-intent complex queries, and error conditions with invalid inputs. Diversity in expected outputs matters equally, spanning simple factual answers, complex explanations, creative responses, conversational exchanges, and structured data generation.
Real-world representation comes from actual user queries extracted from production logs, synthetic examples filling coverage gaps, adversarial inputs testing safety boundaries, and domain-specific scenarios matching your use case. Build test datasets incrementally. Start with 50-100 carefully selected cases. Expand based on test runs revealing gaps in coverage.
Selecting appropriate testing strategies
Different LLM applications need different testing strategies. A customer support chatbot needs different testing focus than a code generation tool. Match testing strategy to use case:
| Category | Testing Focus Areas |
| Conversational AI | Multi-turn dialogue testingContext retention validationPersonality consistency checksGraceful failure handling |
| Content Generation | Quality and creativity assessmentFactual accuracy verificationStyle and tone evaluationPlagiarism detection |
| Information Retrieval | Relevance scoringCoverage completenessCitation accuracyHallucination detection |
| Code Generation | Syntax correctnessFunctional accuracySecurity vulnerability checkingPerformance characteristics |
Automating test execution
Automated testing makes continuous validation practical. Testing frameworks enable running test suites automatically on code changes, model updates, or regular schedules. Critical automation capabilities include integration with CI/CD pipelines, parallel test execution for speed, result tracking and reporting, failure notifications and alerts, and historical trend analysis.
Popular testing frameworks for LLM testing include DeepEval for comprehensive LLM evaluation, LangChain for testing LLM chains, custom frameworks built on pytest, Braintrust for production monitoring, and Evidently for model validation. Each framework brings different strengths matching different testing needs.
Best practices for testing LLM applications
Teams successfully testing LLM models follow proven patterns that balance thoroughness with practicality.
Start with clear evaluation criteria
Define what good outputs look like before testing. Vague quality standards produce unreliable test results. Specific evaluation criteria enable consistent measurement. For each LLM application component:
- List required qualities (accuracy, helpfulness, safety)
- Define success thresholds for each quality
- Document scoring rubrics
- Create example good and bad outputs
- Get stakeholder agreement on standards
Combine automated and manual testing
Automated LLM testing provides scale. Manual testing catches subtleties machines miss. Effective LLM testing combines both.
| Approach | What to Test |
| Automate |
|
| Test Manually |
|
Test at multiple levels
Testing LLM applications works best with a layered approach mirroring the traditional software testing pyramid. Many fast unit tests form the base, fewer integration tests sit in the middle, and selective end-to-end tests cap the structure.
At the unit level, teams validate individual LLM calls, test prompt templates, check single-turn response quality, and verify basic output formats. Integration testing examines multi-component workflows, database and API integration, context passing between calls, and error propagation handling. System testing covers complete user workflows, end-to-end conversation testing, production environment validation, and real-world scenario coverage.
This layered approach catches different types of problems at appropriate levels. Unit tests run quickly and catch basic issues. Integration tests validate components work together. System tests confirm the complete application delivers value to users.
Track test results over time
LLM behavior drifts over time even without code changes. Model updates, training data shifts, and external API changes affect output quality. Continuous testing tracks quality trends.
Monitoring test results enables:
- Early detection of quality degradation
- Validation that improvements actually improve quality
- Understanding seasonal or temporal patterns
- Baseline comparison for new releases
- Data-driven decisions on model updates
Tools like Testomat.io help teams organize test suites, track execution across versions, and monitor quality metrics over time. Centralized test management becomes critical when testing complexity exceeds what spreadsheets handle.
Implement continuous testing in production
Testing isn’t done at deployment. Testing LLM models continues in production through ongoing monitoring and evaluation.
Sampling-based evaluation examines a percentage of production traffic, adjusting sampling rates based on volume. Teams prioritize evaluation of critical interactions while balancing cost versus coverage. User feedback integration collects thumbs up/down ratings, gathers freeform user comments, tracks task completion rates, and measures user satisfaction scores.
Automatic quality checks run safety filters on all outputs, monitor response latency, check for errors and failures, and detect unusual patterns. A/B testing compares prompt modifications, tests model versions side-by-side, evaluates retrieval strategies, and measures business metrics impact. This continuous validation catches problems before they affect many users.
Addressing common LLM testing challenges
Testing LLM applications presents challenges teams must solve for effective quality assurance.
Handling non-deterministic outputs
LLM responses vary between runs. Traditional test assertions checking exact matches fail. Solutions:
- Semantic similarity thresholds
- Ensemble testing
- Constraint-based validation
Managing test dataset quality
Poor test datasets produce misleading results. Dataset quality determines testing value. Datasets must be representative of production usage, diverse across input types, include challenging edge cases, contain clear expected outputs, and get regularly updated with new scenarios.
Address dataset problems by removing ambiguous examples that confuse rather than clarify, adding missing scenario coverage found through production usage, updating outdated references as information changes, balancing difficulty distribution to avoid too many easy or hard cases, and removing biased examples that skew evaluation results. Regular dataset maintenance keeps test quality high as applications evolve.
Evaluating open-ended outputs
Some LLM tasks have no single correct answer. Creative writing, open-ended dialogue, and brainstorming lack ground truth references. Evaluation approaches:
- Multi-dimensional scoring
- Comparative evaluation
- Rubric-based assessment
Scaling testing efforts economically
LLM testing at scale gets expensive. API costs for testing can exceed production costs. Budget constraints require strategic testing. Cost optimization tactics: smart sampling, tiered evaluation, caching and reuse.
Testing across the LLM application lifecycle
Effective LLM testing happens throughout development and operations, not just pre-deployment.
- Development phase testing. During feature development, testing focuses on rapid iteration and experimentation, validating small components early and often.
- Pre-deployment validation. Before production release, comprehensive testing ensures system readiness. Key activities include full regression test suite execution, performance testing under expected load, security and safety validation, bias and fairness evaluation, compliance verification, and monitoring setup validation.
- Production monitoring. After deployment, continuous testing detects issues, failures, and quality drift, tracking key metrics and user interactions.
- Continuous improvement cycles. Testing results drive improvement priorities. Teams analyze test results and production metrics, identify quality gaps and recurring failure patterns, prioritize fixes and enhancements, implement changes, validate improvements through testing, deploy and monitor, and repeat continuously.
Future trends in LLM testing
LLM testing is changing fast, and it doesn’t really behave like traditional QA anymore. You’re dealing with systems that generate different answers every time, where “correct” is often subjective. Because of that, the focus is shifting toward trust. The real question becomes: can you rely on this model in real situations, especially when inputs are messy or edge cases appear?
- Trust over correctness: outputs aren’t binary anymore, so the focus is on reliability, consistency, and whether the model can be trusted in real scenarios
- Continuous evaluation: testing never really “ends” — models and prompts change, so behavior must be monitored over time
- Human-in-the-loop: automation helps, but people are still needed to judge nuance, usefulness, and context
- Multi-model validation: one model generates, another evaluates — adding a layer of quality control
- Security-first mindset: prompt injections, data leaks, and unsafe outputs are becoming core testing concerns
- Shift in QA roles: less repetitive execution, more thinking, analysis, and scenario design
Conclusion
Testing LLM applications requires adapting traditional software testing principles to non-deterministic AI systems. Unlike traditional software testing where exact matches verify correctness, LLM testing involves probabilistic evaluation across multiple quality dimensions.
Successful teams combine automated LLM testing with human evaluation. They use LLM as a judge for scalable subjective assessment. They build comprehensive test suites covering unit tests, functional tests, performance tests, and responsibility testing. They implement continuous testing throughout development and production.
Testing frameworks like Testomat.io help teams organize testing efforts, track results over time, and coordinate between automated and manual testing. As LLM applications move from experiments to production, systematic testing becomes the difference between success and failure.
Start testing early. Build evaluation criteria alongside features. Automate what you can. Evaluate what matters. Monitor continuously. Improve based on data. The future of LLM applications depends on teams that test rigorously while adapting testing practices to AI’s unique characteristics.
Frequently asked questions
What is the accuracy rate of AI-generated tests?

AI-generated tests are typically highly accurate for standard scenarios, especially when based on clear and well-defined requirements. In most cases, they can cover the main flows and common edge cases reliably. However, accuracy depends heavily on the quality of input — vague or incomplete requirements will lead to weaker results. That’s why AI works best as an assistant, not a replacement. A quick human review ensures the tests match real product behavior and business logic.
How do I know if an AI-generated test has hallucinated?
A hallucinated test usually includes steps, data, or behavior that don’t actually exist in your application.
Common signs include:
- references to features that were never implemented
- incorrect assumptions about business logic
- steps that can’t be reproduced in the UI or API
- overly generic or “perfect-looking” flows that ignore real constraints
The simplest way to detect this is to quickly walk through the test or compare it against your requirements. If something feels off or unclear, it probably is.
How do I fix hallucinated or failed AI-generated tests?
Start by identifying what exactly is incorrect, usually it’s a missing detail or wrong assumption. Then refine the input or prompt by adding more context, such as specific rules, edge cases, or system behavior.
In Testomat.io, you can quickly edit the test, adjust steps, update expected results, and link it to the correct requirements. Over time, as you provide better examples and clearer context, AI-generated tests become more aligned with your project. The key is iteration: review, adjust, and reuse improved patterns. AI gets better when your inputs get better.