In automated testing with Selenium WebDriver for browser automation, locating web elements remains challenging, especially when dealing with dynamic content or complex HTML page structures. Without the ability to accurately pinpoint buttons, text fields, links, and other interactive components, even the most well-designed test script may be ineffective. XPath and CSS Selector commonly used methods for element identification to interact with web applications are XPath and CSS Selectors.
To address this challenge, you can use Selenium WebDriver’s locators to find and interact with web elements. While also basic element locators like ID, Name, Class Name, and CSS Selectors often work well, they are insufficient when elements lack unique attributes or their properties change frequently. That’s when you can use XPath to navigate a web page’s complex structure to find specific elements. In this article, we will discover what XPath in Selenium is, explore the different types of XPath, reveal basic and advanced techniques, and learn how to write XPath in Selenium.
What is Selenium?
Being an open-source suite of tools and libraries, Selenium enables teams to make the testing of website functionality automated. With its cross-browser, cross-language, and cross-platform capabilities, they can test across different environments.
Selenium supports Java, JavaScript, C#, PHP, Python, and Ruby programming languages, which allows teams to integrate it with existing development workflows.
Furthermore, it also offers extensive browser compatibility with major web browsers like Chrome, Firefox, Safari, Edge, and Opera to cover all major browsers, while being flexible in terms of its ability to be compatible with different automation testing frameworks like TestNG, JUnit, MSTest, Pytest, WebdriverIO,
Selenium Primary Components
- Selenium WebDriver. It is a programming interface which can be used to create test cases and test across all the major programming languages, browsers, and operating systems. Regarding the cons, it has neither built-in test reporting nor a centralized way to maintain objects or elements.
- Selenium Grid. It is a smart proxy server which allows automation testers to run tests on different machines against different browsers.
- Selenium IDE. It is an easy-to-use browser extension which records your interactions with websites and helps you generate and maintain site automation, tests.
What is XPath in Selenium?
XPath, which is known as an acronym for XML Path Language, is a query language used to uniquely identify or address parts of an XML or HTML document. Generally, you can use it to do the following:
- To query or transform XML documents
- To move elements, attributes, and text through an XML document
- To look for certain elements or attributes with matching patterns
- To uniquely identify or address parts of an XML document
- To extract information from any part of an XML document
- To test the addressed nodes within a document to determine whether they match a pattern
When to use XPath
- When elements do not have unique IDs, names, or class names
- When elements are dynamic or change quickly
- When there is a need to locate elements based on their text content or position, which is relative to other elements
Overview of Basic XPath syntax in Selenium
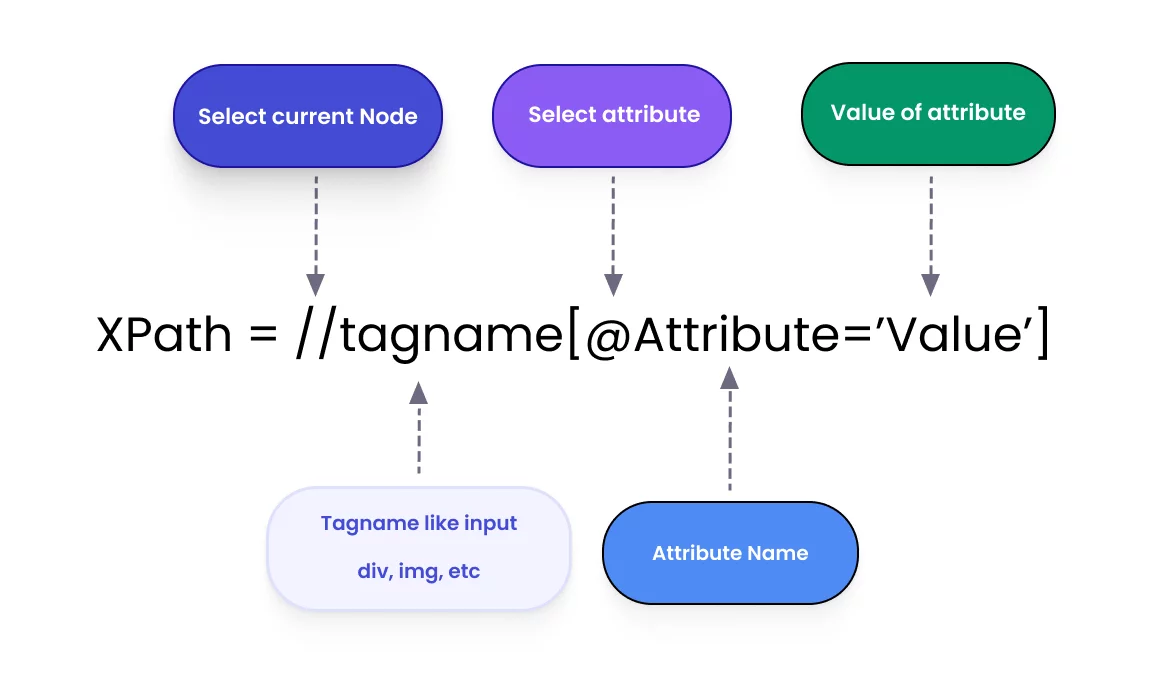
//– it indicates the current node- tagname (e.g.,
div,input,a) – it indicates the tag name of the current node - @attribute (e.g.,
@id,@name,@class) – it indicates the attribute of the node - value (e.g.,
//input[@id='username']) – it indicates the value of the chosen attribute
The Difference Between Static | Dynamic XPath in Selenium
Before we start considering XPath types, it is essential to define “static” and “dynamic” XPath in the context of web elements. It needs to be done because it will determine the choice and robustness of your XPath and will result in effective test automation:
Static XPath. It is a direct and absolute path, which is specified from the root of the webpage to point to an element’s location in the Document Object Model (DOM) hierarchy. But any change in the UI can break the path. Here is XPath in Selenium example:
/html/body/div[1]/div[2]/inputThis path starts from the root and traverses down to the desired element.
Dynamic XPath. It is a relative path that uses flexible criteria to locate dynamic web elements whose attributes or positions change frequently on a webpage. In contrast to Static XPath, the elements in the dynamic XPath are more resilient to changes in the UI. To create dynamic XPathes, you can use the following:
contains(), text(), starts-with()dynamic element indexes- logical operators OR & AND separately or together
- axes methods
Here is xpath examples in selenium:
//input[contains(@id, 'user')]This expression selects any <input> element with an id attribute containing the substring ‘user’.
Sum up: Static VS Dynamic XPath
Static XPath (typically absolute XPath) provides a full path from the HTML root to an element, making it very prone to failure in terms of breaking with any minor change in the page’s HTML structure.
Dynamic XPath locates elements whose properties/positions change frequently to guarantee that test scripts are less prone to failure in the face of UI updates or dynamic content. With dynamic XPath techniques, you can create stable locators, which remain stable despite UI changes, to drastically cut down on test automation maintenance, while you may face frequent test failures by relying on static XPaths in dynamic web applications.
What is an XPath locator?
XPath locator in Selenium WebDriver is a technique used in automation testing to identify web elements and help automation tools like Selenium interact with them even in complex or dynamic DOM structures. They support both absolute and relative paths, providing adaptable element identification via relationships, attributes, or text.
Types of XPath in Selenium
You can use two ways to locate an element in XPath – Absolute XPath and Relative XPath. Let’s review them with some XPath examples in Selenium below:
Absolute XPath
It contains the location of all elements from the root node (HTML), where the path starts, and specifies every node in the hierarchy. However, the whole XPath will fail to find the element if there is any change/adjustment of any node or tag along the defined XPath expression. The syntax begins with a single slash, “/”, and looks like this:
/html/body/div[1]/div[2]/form/input[2]We see that if any new element is added before the target element, or if the structure of the divs, form, or inputs changes, this XPath will fail and break your test automation script.
Relative XPath
As the most commonly used and recommended type, it tells XPath to search for the element anywhere in the document. Starting with a double forward slash “//”, it begins from the middle of the HTML DOM structure without the need to initiate the path from the root element (node). The syntax looks like this:
//input[@id='username'] or //button[text()='Submit']How To Create XPath in Selenium
When writing XPath in Selenium, you can do it by applying various types of XPath locators. Let’s consider them:
- Using Basic Attributes
- Using Functions
- Using Axes
Using Basic Attributes
| XPath’s locators | Description | Example |
| By Id | By IdIt allows you to identify an element by its id attribute. | driver.findElement(By.xpath(“//*[@id=’username’]”)) |
| By Class Name | It allows you to locate an element by its class name. | driver.findElement(By.xpath(“//*[@class=’login-button’]”)) |
| By Name | It allows you to locate elements by their name attribute. | driver.findElement(By.xpath(“//*[@name=’password’]”)) |
| By Tag Name | It allows you to detect elements by their HTML tag name. | driver.findElement(By.xpath(“//p”)) |
Using XPath Functions in Selenium
XPath’s functions are used to determine elements by their attributes, positions, and other factors.
| XPath’s locators | Description | Example |
| By Text | It allows you to detect elements based on their inner text. | driver.findElement(By.xpath(“//*[text()=’Submit’]”)) |
| Using Contains | It defines elements based on a substring of one of their attribute values. | driver.findElement(By.xpath(“//*[contains(@href,’testomat.io’)]”)) |
| Using Starts-With | It allows you to find elements based on an attribute’s prefix. | driver.findElement(By.xpath(“//*[starts-with(@id,’user’)]”)) |
| Using Ends-With | It allows you to find elements with attribute values which end with a specific string. | driver.findElement(By.xpath(“//*[ends-with(@id,’name’)]”)) |
| Using Logical Operations | It uses logical operations to find elements that satisfy all specified criteria. | //button[@class = “command-button” and @disabled=”true” )] |
Using XPath axes in Selenium
With Axis, you can see the relationship to the current node and locate the relative nodes concerning the tree’s current node. So, the XPath Axis uses the relation between several nodes to find those nodes in the DOM structure:
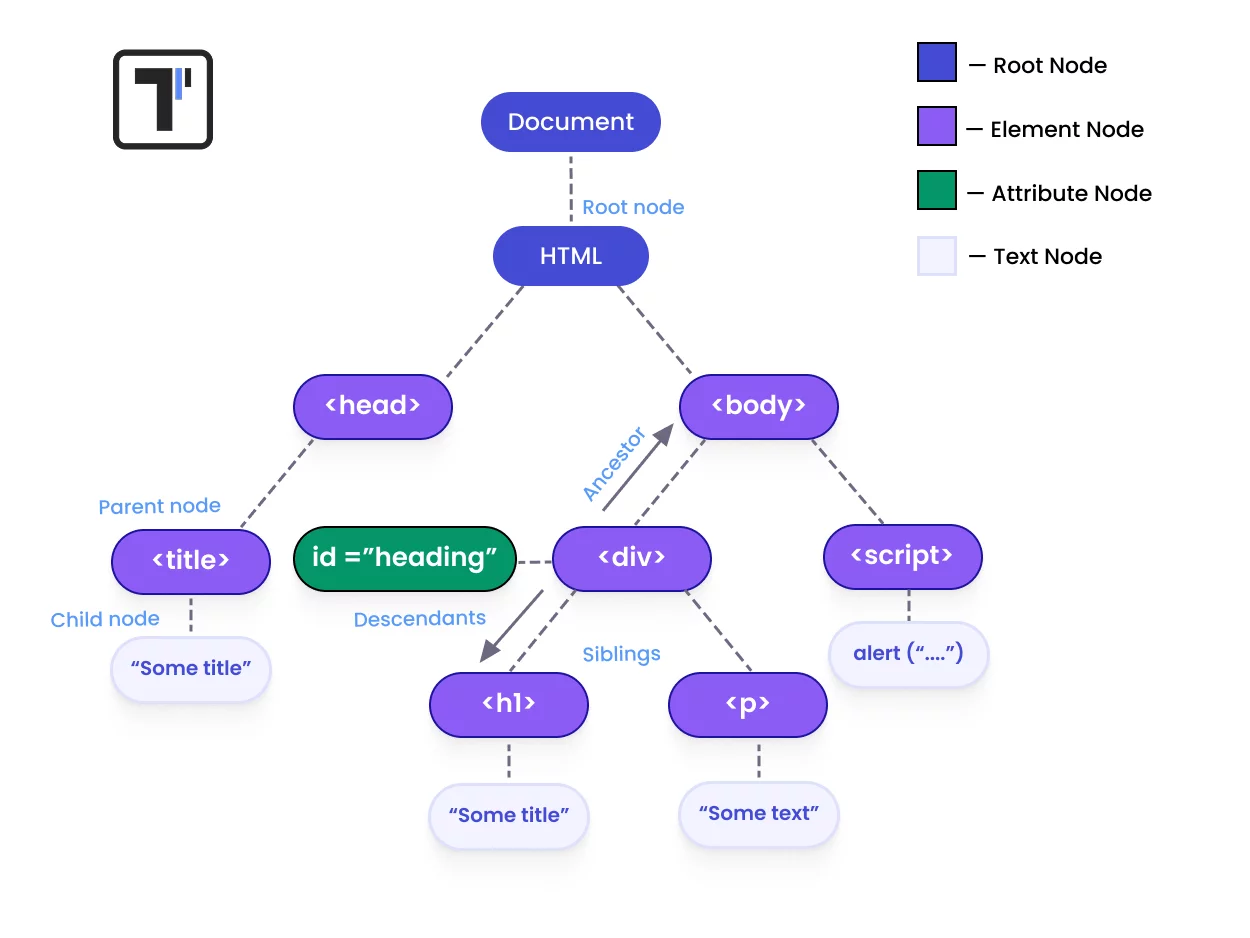
Below you can find commonly used XPath axes:
| XPath’s locators | Description | Example |
| parent | It selects the immediate parent. | //input[@id=’username’]/parent::div |
| child | It selects direct children. | //div[@class=’form-group’]/child::input |
| ancestor | It selects all ancestors (parent, grandparent, and so on). | //input[@id=’username’]/ancestor::form |
| descendant | It selects all descendants (children, grandchildren, and so on.) | //div[@id=’container’]/descendant::a |
| following-sibling | It selects all siblings after the current node. | //input[@id=’firstName’]/following-sibling::input |
| preceding | It chooses everything in the document before the current node’s opening tag | //p/preceding::h1 |
| preceding-sibling | It selects all siblings before the current node | //input[@id=’lastName’]/preceding-sibling::input |
We would like to mention that you can apply chained XPath in Selenium concept, where you can utilize multiple XPaths in conjunction to locate an element that might not be uniquely identifiable by a single XPath expression. In other words, instead of writing one absolute XPath, you can separate it into multiple relative XPaths. When chaining XPaths, you can improve the accuracy and robustness of the element location strategy, thus making the automation scripts more stable.
How to Use XPath in Selenium: Practical Examples
Example 1: Locating an Element by ID
The simplest way to locate elements using XPath is by their unique identifier, which is, as a rule, the id attribute. It looks like this:
WebElement element = driver.findElement(By.xpath("//input[@id='username']"))In this example, you can use the <input> element where the id is “username.” With the findElement method, you can return the element for further interaction, checking its presence, or entering data.
Example 2: Traversing Using Axes
In this example, we consider an advanced technique to traverse the DOM’s structure based on how elements relate to each other.
WebElement parentelement = driver.findElement(By.xpath("//span[@class='label']/parent::div"))We can see that the parent axis is applied to find the parent <div> element of a <span> with the class “label”. When an element, which you’re aiming to locate, has no unique identifying attributes, but can be found by its relationship to parent or sibling elements, XPath’s axes can be useful to achieve this goal.
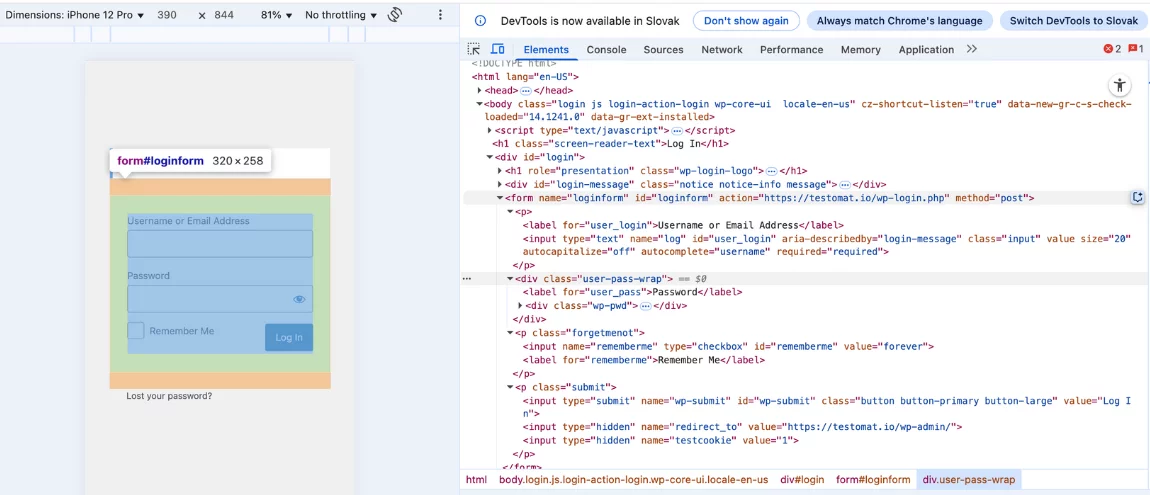
html
└── body
└── div#form
├── label (Username or Email)
├── input (name="log")
├── label (Password)
├── div (class="wp-pwd")
├── input (name="rememberme")
├── label (Remember Me)
└── button (Log in)
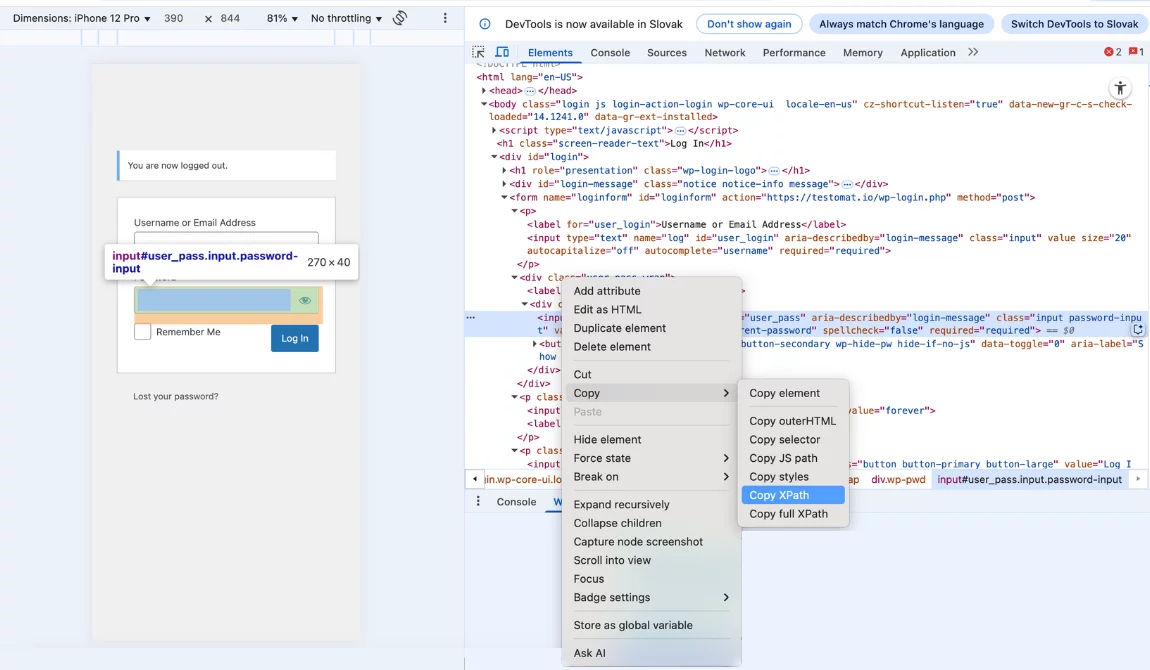
Result of copying XPath with Developers’ tools are the next:
Example 3: Copy Xpath
//*[@id="user_pass"] //Copy XPathExample 4: Copy full XPath
/html/body/div[1]/form/div/div/input.What Are the Advantages of XPath Locators?
- With XPath, complex searches are becoming more flexible to allow you to locate items using a wide range of parameters.
- When you work with web pages with dynamic content, XPath can easily adapt to changes in page structure.
- It can traverse the DOM in both directions, which means moving from parents to children or from children to parents and siblings, to target elements that are structurally related to a known and stable element.
What Are the Disadvantages of XPath Locators?
- Complex XPath queries may be more slowly compared to simpler locators like CSS selectors.
- When relying on specific structures or attributes, XPath expressions may fail if the page structure changes.
Best Practices for Using XPath in Selenium
Here are some of the tips to follow when using XPath in Selenium:
- You need to use relative XPath to write more adaptable and maintainable locators compared to absolute XPath, which is based on the complete path from the root node.
- You need to keep XPaths as short and specific as possible to make them easier to maintain and improve.
- You need to apply functions like
contains(),starts-with(), andtext()if there is a need to create XPath expressions for processing dynamic elements with changing attributes. Thecontains()function is suitable when attributes such as id or class have variable values. - When direct attributes aren’t enough, you can opt for XPath axes to locate elements through their relative position to a stable and identified element.
- Before incorporating an XPath into your code, you should test it directly in the browser’s console to make certain it works correctly.
Topics interesting for you:
Bottom Line: Ready to use XPath in Selenium?
Applying XPath in Selenium while conducting the automated testing process is useful and effective for your teams. Whether they use a simple XPath or a more complex one, choosing the right XPath is crucial for test case stability. Being a powerful tool, it provides a flexible way to build robust Selenium test scripts that can handle a variety of web page structures with dynamic content and make sure they won’t fail if any of these locators change later.
👉 Drop us a line if you want to learn more additional information about XPath in Selenium, and the testomat.io team is glad to provide software test automation services
Frequently asked questions
What is XPath in Selenium and why is it used?

XPath (XML Path Language) is a query language used to locate elements in XML documents and HTML pages. In Selenium, XPath helps you find elements on a web page—especially when there are no unique IDs or names—by navigating the HTML structure using tags, attributes, and text.
What’s the difference between absolute and relative XPath in Selenium?
-
Absolute XPath starts from the root (
/html) and follows the full path to the element. Example:/html/body/div[2]/ul/li[3]/a. It’s fragile—changes in the page structure can break it. -
Relative XPath starts from the middle of the document using
//and doesn’t require the full path. Example://a[@id='login']. It’s more flexible and preferred in most cases.
How do you write an XPath in Selenium to locate an element by text?
You can use the text() function. For example:
This finds a <button> element with the visible text “Submit”. You can also use contains() for partial matches: