
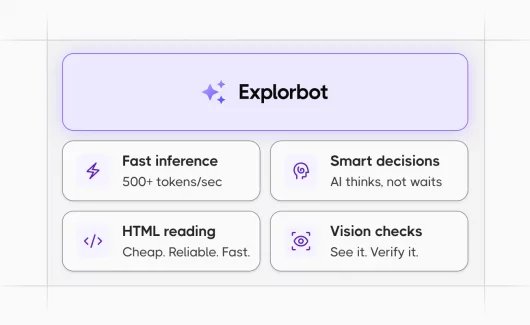
Explorbot is an open-source AI agent that explores web applications on its own. The first question people ask when they watch it run is always the same: how does it think so fast? They expect AI tools to be slow, hungry, and expensive. Explorbot is none of those things.
The short answer is that Explorbot uses two AI models with very different jobs, served by inference providers built for speed rather than training. The long answer is what the rest of this post is about.
Why testing needs speed
Testing a web application generates a lot of raw data. On every step, the agent reads HTML snapshots, ARIA trees, and sometimes screenshots. That’s the bulk of the work: perception, not reasoning. The actual decision (which element to interact with next) is comparatively simple. Click a button, fill a field, check whether a modal appeared. Nothing close to the complexity of generating code or reasoning through a multi-step problem.
A model that spends 30 seconds deciding which button to click is not useful here. Take a test with 30 steps: even if 20% of them lead somewhere wrong, a fast model recovers quickly. It explores a path, hits a dead end, backtracks, and tries the next option, all within the same time a slow “thinking” model would spend deliberating on step one.
The occasional wrong click is not a failure. It’s how exploratory testing works. Speed to recover matters more than certainty on each step.
The threshold that changes how the agent feels
On fast AI providers, the time for a model to respond is comparable to the time a browser takes to react to a click. A Playwright click (locate the element, fire the click, wait for the state change) takes roughly the same time as a single AI request.
One AI request, one browser interaction
Cross that threshold and the agent stops feeling like an AI tool. It starts feeling like another tab in your devtools, doing the same work at the same speed.
A quick primer on inference providers
Not all AI providers are built the same. OpenAI and Anthropic train their own models and run them on conventional GPU clusters built for training. Others specialise in inference: the act of running a model that someone else has trained, as fast and cheaply as possible.
Groq, Cerebras , and SambaNova are inference providers. They built custom silicon specifically for serving models, not training them. Different hardware, different performance profile.
Groq is the main provider behind Explorbot’s speed. Groq builds their own chips (not GPUs) designed from the ground up for running large language models. Groq doesn’t develop models; it serves open-weight models from Meta, OpenAI, and others at speeds GPU-based providers struggle to match. The result is consistently high throughput at some of the lowest prices in the industry.
When OpenAI released gpt-oss under Apache 2.0 in August 2025, Groq was among the first to serve it. For the second model slot, OpenRouter fills the gap: a meta-provider with one API key that routes to the fastest available provider across the market.
Recommended models for Explorbot
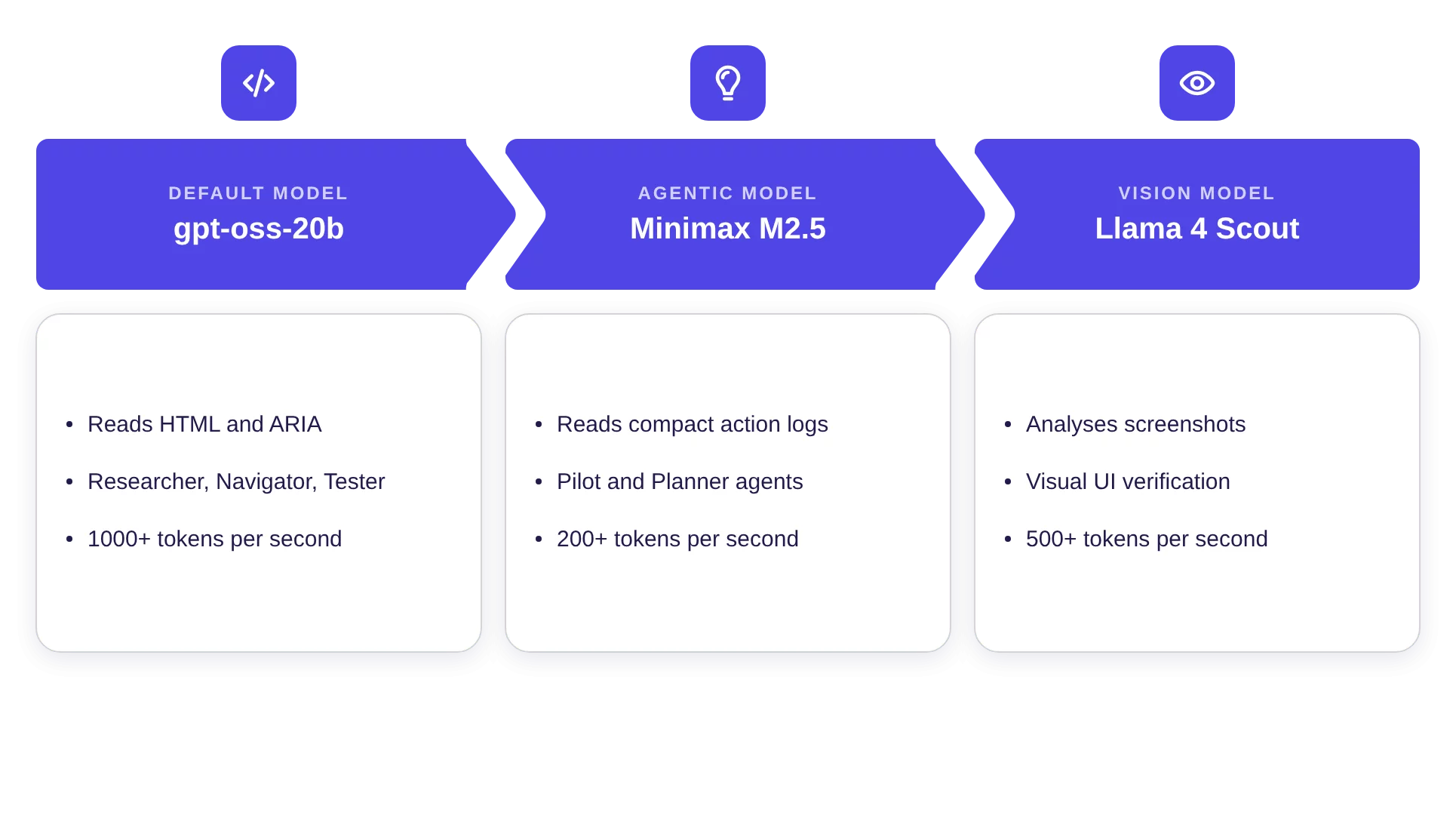
Throughput below is measured in TPS — tokens per second, the rate at which a model produces output. Higher TPS means the agent waits less between steps.
| Config key | Model | Provider | Throughput | Pricing |
|---|---|---|---|---|
model |
gpt-oss-20b | Groq | 1000+ TPS | $0.03 input / $0.14 output per 1M tokens |
agenticModel |
Minimax M2.5 | OpenRouter :nitro | 200+ TPS | $0.26 input / $1.00 output per 1M tokens |
visionModel |
Llama 4 Scout | Groq | 500+ TPS | $0.11 input / $0.34 output per 1M tokens |
- gpt-oss-20b is the default model: a 21-billion-parameter mixture-of-experts model with only 3.6 billion active parameters per token. Small enough to run on a single GPU, cheap to serve at scale. Researcher, Navigator, and Tester use it on every iteration to read full HTML and ARIA snapshots.
- Minimax M2.5 is the agentic model, used by Pilot and Planner. It makes high-level decisions based on compact action logs, not raw HTML. OpenRouter’s `:nitro` routing dispatches requests to the fastest available provider in real time.
- Llama 4 Scout is the vision model. It handles visual checks: when something is genuinely visual (did the toast appear, is this element highlighted), a screenshot is faster and more reliable than parsing the DOM.
The real split: cheap and fast, vs expensive and smart
Most AI testing tools pick one model and feed it everything. Explorbot does not.
Explorbot uses two tiers of fast model, paired by job:
| Cheap and fast | Expensive and smart | |
|---|---|---|
| Model | gpt-oss-20b | Minimax M2.5 |
| Input price | $0.03 / 1M tokens | $0.26 / 1M tokens |
| Output price | $0.14 / 1M tokens | $1.00 / 1M tokens |
| Throughput | 1000+ TPS | 200+ TPS |
| Job | Reads HTML and executes fast repetitive tasks | Makes decisions, explores flows, and plans actions |
Both columns are fast. The split is not speed. It is **cost per token against reasoning quality**, applied to the right context size.
Why HTML lives in the cheap column
HTML snapshots are big. A modest application page produces five to twenty thousand tokens of cleaned HTML once you include the structure, attributes, and ARIA roles needed for reliable selectors. Multiply that by thirty iterations in a test, and the agent is sending hundreds of thousands of input tokens through whichever model reads it.
You cannot do that on the expensive tier. At $1 per million output tokens it adds up fast. At $0.14 per million it is rounding error.
So Researcher, Navigator, and Tester (the agents that read the page on every step) all run on `gpt-oss-20b`. Token-hungry by nature, and the cheap tier keeps that cost negligible.
Why decisions live in the expensive column
Pilot, Planner, and the other decision-making agents never read the full HTML. They read a researcher-built page summary plus the last few tool executions. A few hundred tokens of context, not twenty thousand.
That tiny context is what makes the expensive smart tier affordable here. The per-token price is higher, but it applies to a fraction of the tokens. Pilot’s reviews are some of the most important calls Explorbot makes, and Minimax M2.5 reasons through them well.
Screenshots are also fast
A common assumption is that vision-capable models are slow. They were once. Today, **Llama 4 Scout on Groq runs above 500 tokens per second** with multimodal input. Explorbot uses it for visual checks (did the toast appear, is this button highlighted), and the screenshot path is not the bottleneck people assume.
Explorbot still defaults to HTML for the main loop because text is more reliable for selectors and structure. But vision is a tool, not a tier to avoid.
Recommended setup
{
model: groq('openai/gpt-oss-20b'), // tester, researcher, navigator
visionModel: groq('meta-llama/llama-4-scout-17b-16e-instruct'), // see() tool
agenticModel: openrouter('minimax/minimax-m2.5:nitro'), // pilot, planner, decisions
}Why not Playwright-MCP and Cursor
Playwright-MCP lets you drive browsers from an AI IDE like Cursor. But MCP consumes roughly 4x more tokens than direct CLI approaches for the same task—the accessibility snapshots are expensive. More importantly, MCP workflows are interactive: you guide the agent through chat. Explorbot is autonomous. It runs overnight without you. Different tools, different jobs.
Takeways
The interesting part of Explorbot isn’t the model list. It’s the principle behind it: match the model to the shape of the work, not to the prestige of the brand.
Perception is bulk work on huge context. It wants a cheap, fast model. Decisions are surgical work on tiny context. They want a smarter, slightly slower one. Once you see that split, the model choice becomes obvious, and the bill stops looking scary.
The same principle holds outside testing. Any AI workflow that mixes “read this giant document” with “decide what to do about it” can be split the same way. We just happen to do it for browsers.
Test the claims
Everything above is a claim: that gpt-oss-20b is fast enough, that Minimax M2.5 reasons well enough, that $1 an hour covers a real testing run. None of it is hard to verify. The install takes a minute.
bash
npm i explorbot
npx explorbot initSet model: openai/gpt-oss-20b on Groq, point your agentic slot at Minimax M2.5 on OpenRouter, and run it against your own app.
- GitHub: github.com/testomatio/explorbot
- Docs: docs.testomat.io
- Sync results with Testomat.io for unified test reporting